Большой вопрос про большие данные
Содержание:
- Где используются больше данные
- Что такое Big Data и когда они появились
- История возникновения
- Внедрение технологий больших данных в различных отраслях
- Кто такой аналитик Big Data?
- Где можно получить образование по Big Data (анализу больших данных)?
- Сдерживающий фактор
- Почему большие данные должны быть качественными или что такое Data Quality
- Зачем государству ваши данные?
- Big data — простыми словами
- Что такое Big data?
- Когда стоит внедрять платформы для анализа больших данных
- Это искусственный интеллект?
- История вопроса и определение термина
- Big Data (БигДата): что это такое
- Перспективы и тенденции развития Big data
- Особенности применения технологии больших данных в отличие от работы с базами данных
- Минимальные навыки и обучение с нуля
- Кто и как собирает данные?
Где используются больше данные
• Облачные хранилища. Хранить всё на локальных компьютерах, дисках и серверах неудобно и затратно. Крупные облачные data-центры становятся надёжным способом хранения информации, доступной в любой момент.
• Блокчейн. Революционная технология, сотрясающая мир в последние годы, упрощает транзакции, делает их безопаснее, а, главное, хорошо справляется с обработкой операций между гигантским количеством контрагентов за счёт своего математического алгоритма.
• Самообслуживание. Роботизация и промышленная автоматизация снижают расходы на ведение бизнеса и уменьшают стоимость товаров или услуг.
• Искусственный интеллект и глубокое обучение. Подражание мышлению головного мозга помогает делать отзывчивые системы, эффективные в науке и бизнесе.
Эти сферы создаются и прогрессируют благодаря сбору и анализу данных. Пионерами в области таких разработок являются: поисковые системы, мобильные операторы, гиганты онлайн-коммерции, банки.
Что такое Big Data и когда они появились
С развитием информатики как науки практически все сферы жизни можно представить как информационные потоки. Информация существует в самых разных формах и видах, некоторые из них поддаются обработке – в том числе и машинной. На этом основаны все современные информационное технологии – от программного обеспечения в «умной» бытовой технике до мощнейших суперкомпьютеров.
Но относительно недавно в обиходе появляется новое понятие – кроме технологии блокчейн речь пошла о Big Data. С одной стороны, все просто – если обработать много данных, можно получить действительно важную информацию. С другой – это подают как совершенно новое перспективное направление. Но так ли это?
Как рассказал нам кандидат физико-математических наук Александр Богуцкий, хоть понятие Big Data и относительно молодое, само по себе явление уходит корнями как минимум в середину прошлого века. Проблема обработки больших массивов данных, в общем-то, существовала уже давно – данных становилось все больше, но вот извлекать из них полезные знания становилось все сложнее. Тогда – около 80 лет назад – это назвали «информационным взрывом», ответом на него стало появление технологий машинного обучения (Machine Learning) на стыке прикладной статистики, математики и информатики.
А уже из этого появляются Big Data, отмечает эксперт:
В той или иной форме обработка больших массивов данных применялась на практике уже достаточно давно. Например, еще с 80-х годов прошлого века приход технологий в торговлю и финансы позволил корпорациям более гибко управлять товарным ассортиментом – данные от сканирования штрих-кодов и оплаты через банковские терминалы попадали в автоматизированную систему, которая анализировала поведение покупателей.
Второй этап развития анализа данных обычно относят уже к первой половине нулевых – тогда оказалось, что аналитические данные обходятся компаниям слишком дорого, а используют их, как правило, лишь высшие руководители. Параллельно в мире развиваются IT-платформы, мобильные технологии, облачные сервисы, а сама обработка данных становится дешевле. Именно тут, как считается, зародились «большие данные».
Третий же этап, как считается, несет миру возможность анализировать информацию в режиме реального времени. Это будущее, которое уже здесь – в Big Data включают, например, данные со смартфонов, телевизоров, дорожных камер и многого другого. Параллельно миру приходится решать проблемы доступа к персональным данным и риски утечки информации – но это уже совсем другая история.
Говоря же проще, Big Data – это набор технологий и методов для обработки и анализа больших объемов данных, говорит Алексей Чащегоров из «Яндекса». По его словам, суть этого направления – в разнородной структуре данных, которые обрабатываются одновременно:
Но главное, что нужно знать о Big Data – это то, что они уже давно и активно используются.
История возникновения
Название Big Data появилось в 2000-х, но концепция обработки большого количества данных возникла гораздо раньше. Менялся только объем и масштаб. В 1960-х годах начали создаваться первые хранилища больших данных, а сорок лет спустя компании увидели, сколько наборов данных можно собрать с помощью онлайн-сервисов, сайтов, приложений и любых продуктов, с которыми взаимодействуют клиенты. Именно тогда начали набирать популярность первые сервисы Big Data (Hadoop, NoSQL и т.д.). Наличие таких инструментов стало необходимо, поскольку они упрощают и удешевляют хранение и анализ.
Большие данные часто характеризуются тремя факторами: большим объемом, большим разнообразием типов данных, хранящихся в системах, и скоростью, с которой данные генерируются, собираются и обрабатываются. Эти характеристики были впервые выявлены Дугом Лэйни, аналитиком в Meta Group Inc., в 2001 году. Компания Gartner популяризировала их после того, как в 2005 году приобрела Meta Group. Постепенно к этим описаниям больших данных стали добавляться и другие критерии (достоверность, ценность и так далее).
В 2008 году с Клиффорд Лина в спецвыпуске журнала Nature эксперт назвал взрывной рост потоков информации big data. В него он отнес любые массивы неоднородных данных свыше 150 Гб в сутки. С тех пор термин «большие данные» прочно укрепился.
Внедрение технологий больших данных в различных отраслях
/¦ ¦ / ¦ ¦ / ¦ ¦ ¬ ¦ ¦ ¦ --+--¬ ¦ Здравоохранение¦ ¦ ¦13 ¦ ¦ L-T--- ¦ + ¦ ¦ ¦ --+---¬ ¦ Образование¦ ¦ ¦15 ¦ ¦ L-T---- ¦ + ¦ ¦ ¦ --+-----¬ ¦ Бизнес-сервис/Консалтинг¦ ¦ ¦18 ¦ ¦ L-T------ ¦ + ¦ ¦ ¦ --+--------------¬ ¦ Логистика и транспорт¦ ¦ ¦33 ¦ --¬ ¦ L-T--------------- ¦ ¦ ¦ + ¦ ¦ L-- ¦ --+--------------¬ ¦Ряд 1 Финансы и страхование¦ ¦ ¦33 ¦ ¦ L-T--------------- ¦ + ¦ ¦ ¦ --+----------------¬ ¦ IT-компании¦ ¦ ¦36 ¦ ¦ L-T----------------- ¦ + ¦ ¦ ¦ --+------------------¬ ¦Государственное предприятие¦ ¦ ¦38 ¦ ¦ L-T------------------- ¦ + ¦ ¦ ¦ --+--------------------------¬ ¦ Инжиниринг и...¦ ¦ ¦45 ¦ ¦ L-T--------------------------- ¦ + ¦ ¦ ¦ --+------------------------------¬ ¦ Телекоммуникационные...¦ ¦ ¦58 ¦ ¦ L--------------------------------- / ¦ / / ¦/ / +-----------T-----------T-----------¬ 0 20 40 60
Рис. 2
На сегодняшний день Big Data активно внедряются в зарубежных компаниях. Такие компании, как Nasdaq, Facebook, Google, IBM, VISA, Master Card, Bank of America, HSBC, AT&T, Coca-Cola, Starbucks и Netflix уже используют ресурсы больших данных.
В целом объем рынка вырастет с 1,345 млрд евро в 2015 г. до 3,198 млрд евро в 2019 г., средний темп роста составит 24%.
Компаниями финансового сектора, по данным Bain Company’s Insights Analysis, будут произведены значительные инвестиции, средний темп роста инвестиций составит 22% до 2020 г. Интернет-компании планируют потратить 2,8 млрд долл. США, средний темп роста увеличения затрат на большие данные составит 26%.
По прогнозам IDC тенденции развития рынка выглядят следующим образом <6>:
- в следующие 5 лет затраты на облачные решения в сфере технологий больших данных будут расти в 3 раза быстрее, чем затраты на локальные решения. Станут востребованными гибридные платформы для хранения данных;
- рост приложений с использованием сложной и прогнозной аналитики, включая машинное обучение, ускорится в 2017 г., рынок таких приложений будет расти на 65% быстрее, чем приложения, не использующие прогнозную аналитику;
- медиа аналитика утроится в 2017 г. и станет ключевым драйвером роста рынка технологий больших данных;
- ускорится тенденция внедрения решений для анализа постоянного потока информации, которая применима для «Интернета вещей»;
- к 2018 г. 50% пользователей будут взаимодействовать с сервисами, основанными на когнитивном вычислении.
<6> Аналитический обзор рынка Big Data.
В.И.Берестова
Доцент
РГГУ
Кто такой аналитик Big Data?
Big Data – это большой объем данных, которые изо дня в день наводняют бизнес в увеличивающихся объемах и все более с высокой скоростью. Эти объемы настолько огромны, что традиционное программное обеспечение для их обработки просто не может ими управлять. Но они могут быть использованы компаниями для решения бизнес-задач и принятия эффективных решений.
По сути, аналитик Big Data является специалистом по обработке данных, но с существенной разницей – в отличие от традиционного аналитика, который в основном имеет дело со структурированными данными, специалист по Big Data работает с неструктурированными и полуструктурированными данными.
Работа аналитика Big Data состоит в том, чтобы изучать рынок, выявляя, собирая, анализируя, визуализируя информацию, которая может быть полезна для бизнеса.
Если обобщить, то специалист должен:
- Собирать и накапливать данные из разрозненных источников, очищать их, организовывать, обрабатывать и анализировать, чтобы извлечь ценные идеи и информацию.
- Выявлять новые источники и разрабатывать методы улучшения интеллектуального сбора (Data Mining), анализа и отчетности.
- Писать SQL-запросы для извлечения информации из хранилища данных.
- Представлять результаты в отчетах (в виде таблиц, диаграмм или графиков), чтобы помочь команде управления в процессе принятия решений.
- Разрабатывать реляционные БД для поиска и сбора данных.
- Применять методы статистического анализа для исследования и анализа потребительских данных.
- Отслеживать тенденции и корреляционные закономерности между сложными наборами данных.
- Выполнять рутинные аналитические задачи для поддержки повседневного функционирования бизнеса и принятия решений.
- Сотрудничать с учеными в области обработки данных для разработки инновационных аналитических инструментов.
- Работать в тесном сотрудничестве как с IT-командой, так и с командой управления бизнесом для достижения целей компании.
Способность быстро и эффективно обрабатывать большие данные дает возможность быть конкурентоспособными среди множества организаций.
Где можно получить образование по Big Data (анализу больших данных)?
GeekUniversity совместно с Mail.ru Group открыли первый в России факультет Аналитики Big Data.
Для учебы достаточно школьных знаний. У вас будут все необходимые ресурсы и инструменты + целая программа по высшей математике. Не абстрактная, как в обычных вузах, а построенная на практике. Обучение познакомит вас с технологиями машинного обучения и нейронными сетями, научит решать настоящие бизнес-задачи.
После учебы вы сможете работать по специальностям:
- .
- Искусственный интеллект,
- Машинное обучение,
- Нейронные сети.
Особенности изучения Big Data в GeekUniversity
Через полтора года практического обучения вы освоите современные технологии Data Science и приобретете компетенции, необходимые для работы в крупной IT-компании. Получите диплом о профессиональной переподготовке и сертификат.
Обучение проводится на основании государственной лицензии № 040485. По результатам успешного завершения обучения выдаем выпускникам диплом о профессиональной переподготовке и электронный сертификат на портале GeekBrains и Mail.ru Group.
Проектно-ориентированное обучение
Обучение происходит на практике, программы разрабатываются совместно со специалистами из компаний-лидеров рынка. Вы решите четыре проектные задачи по работе с данными и примените полученные навыки на практике. Полтора года обучения в GeekUniversity = полтора года реального опыта работы с большими данными для вашего резюме.
Наставник
В течение всего обучения у вас будет личный помощник-куратор. С ним вы сможете быстро разобраться со всеми проблемами, на которые в ином случае ушли бы недели. Работа с наставником удваивает скорость и качество обучения.
Основательная математическая подготовка
Профессионализм в Data Science — это на 50% умение строить математические модели и еще на 50% — работать с данными. GeekUniversity прокачает ваши знания в матанализе, которые обязательно проверят на собеседовании в любой серьезной компании.
GeekUniversity дает полтора года опыта работы для вашего резюме
В результате для вас откроется в 5 раз больше вакансий:
Для тех у кого нет опыта в программировании, предлагается начать с подготовительных курсов. Они позволят получить базовые знания для комфортного обучения по основной программе.
Самые последние новости криптовалютного рынка и майнинга:
Исследование Fidelity: 52% крупнейших инвесторов уже владеют криптовалютой
«Народная партия» Канады выступила с критикой Центробанка и поддержала биткоин
Эмитенты стейблкоинов обязаны обеспечить свободную конвертацию токенов в фиат
Создатель биткоина Сатоши Накамото увековечен в виде бронзовой статуи в Венгрии
Как изменилась комиссия за транзакции в сети Ethereum после обновления London?
The following two tabs change content below.
Mining-Cryptocurrency
Материал подготовлен редакцией сайта «Майнинг Криптовалюты», в составе: Главный редактор — Антон Сизов, Журналисты — Игорь Лосев, Виталий Воронов, Дмитрий Марков, Елена Карпина. Мы предоставляем самую актуальную информацию о рынке криптовалют, майнинге и технологии блокчейн. Отказ от ответственности: все материалы на сайте Mining-Cryptocurrency.ru имеют исключительно информативные цели и не являются торговой рекомендацией или публичной офертой к покупке каких-либо криптовалют или осуществлению любых иных инвестиций и финансовых операций.
Новости Mining-Cryptocurrency
- Фьючерсы на биткоин — что это такое, для чего нужны и где можно торговать? — 07.10.2020
- Что такое Big Data простыми словами? Применение и перспективы больших данных — 20.04.2020
- United Traders — инвестиции в IPO американских компаний и криптовалюту — 16.08.2019
- Что такое маржинальная торговля криптовалютой с плечом — принципы и биржи — 22.07.2019
- Жители Канады теперь смогут оплачивать налоги на недвижимость в биткоинах — 22.07.2019
Сдерживающий фактор
Ряд преград затрудняют использование данных, полученных от других пользователей, не нарушив их приватность, — умные устройства сильно связаны с частной жизнью своих владельцев. Кроме того, необходимо тщательно продумать вопрос безопасности. Использование умного обогревателя не должно привести к пожару, а плита не должна допустить утечки газа.
Из этого вытекает еще одна проблема — на кого ложится юридическая ответственность в несчастных случаях, связанных с использованием IoT? Неопределенность в отношении этих вопросов препятствует ведению бизнеса в области интернета вещей и, соответственно, внедрению промышленных решений Big Data.
Почему большие данные должны быть качественными или что такое Data Quality
Большие данные полезны только когда из них можно извлечь ценные для бизнеса сведения – инсайты. Чтобы анализировать множество файлов или записей Big Data, эти информационные наборы должны обладать не только определенной структурой, но и отвечать следующим характеристикам :
- актуальность – соответствие данных отражают реальному состоянию целевого объекта в текущий период времени;
- объективность – точность отражения данными реального состояния целевого объекта, которая зависит от методов и процедур сбора информации, а также от плотности регистрируемых данных;
- целостность – полнота отражения данными реального состояния целевого объекта, которая показывает, насколько полны, безошибочны и непротиворечивы данные по смыслу и структуре (формату) с сохранением их правильной идентификации и взаимной связанности;
- релевантность – соответствие данных о реальном состоянии целевого объекта и решаемым задачам, что характеризует возможность их применения с учетом содержания, структуры и формата;
- совместимость – процедурный показатель, который характеризует возможность обрабатывать и анализировать данные в дальнейшем, не только в рамках текущей задачи;
- измеримость – качественные или количественные характеристики реального состояния целевого объекта и конечный объем набора цифровых данных.
- управляемость – возможность целевым и осмысленным образом обработать, передать и контролировать данные о реальном состоянии целевого объекта, на основе структуры и формата датасета;
- привязка к источнику данных – связанная и достоверная идентификация цепочки поставки данных, например, указание авторства, источника генерации и прочие атрибуты происхождения данных (Data Provenance);
- доверие к поставщику данных – оценка получателем деловых качеств поставщика публичных данных как ответственного, авторитетного, организованного и относительно независимого издателя цифровой информации высокого качества.
Совокупность количественных оценок каждого из этих показателей отражает качество данных (Data Quality) – характеристику, показывающую степень их пригодности к обработке и анализу, а также соответствие обязательным и специальным требованиям . В упрощенном понимании качество данных – это степень их пригодности к использованию. В частности, стандарт ISO 9000:2015 именно так определяет качество данных по степени их удовлетворения требованиям: потребностям или ожиданиям, таким как полнота, достоверность, точность, последовательность, доступность и своевременность .
На практике оценка качества данных сильно зависит от контекста их использования. Например, для крупных маркетинговых кампаний может быть приемлемо до 3-5% дублированных или пропущенных записей, а в случае с медицинскими исследованиями такое недопустимо. Поэтому дисциплина интеллектуального анализа данных (Data Mining) выделяет целых 5 процедур подготовки информационных наборов к использованию в машинном обучении. Подробнее об этом мы рассказывали здесь
Однако, качество данных важно не только для точности алгоритмов Machine Learning. Устаревшие или ненадежные данные могут привести к дорогостоящим ошибкам, например, лишним расходам на закупку материалов из-за отсутствия актуальных сведений о складских запасах
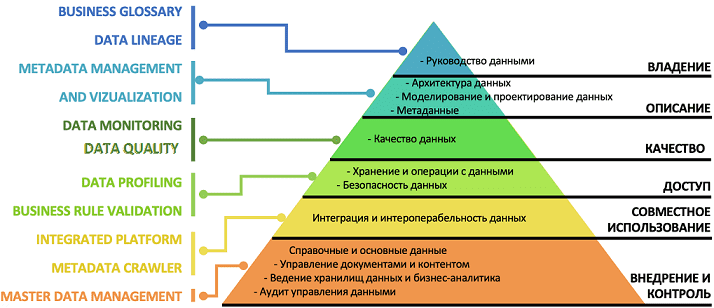
Пирамида процессов Data Management для работы с корпоративными данными
Зачем государству ваши данные?
Как мы уже поняли, корпорации научились использовать данные своих клиентов (и просто разных людей) с собственной выгодой. Учитывая масштабы, речь идет об обезличенных данных, но все равно вопрос безопасности при использования такой информации остается открытым. Но возможность оперировать массивами данных интересует не только частные компании, было логично, что они заинтересуют и государства.
Многие россияне впервые услышали о «больших пользовательских данных» от генерального директора InfoWatch Натальи Касперской. Она в 2016 году заявила, что поисковые запросы, данные о геолокации, контактные данные, сообщения, фото и видео, которые собирают крупные IT-компании вроде Facebook, должны принадлежать государству. Сделать это она предлагает, законодательно заставив компании передавать сертификаты безопасности правительственным органам или просто переводить все эти данные в Россию (кстати, формально такой закон уже давно существует). И это осталось бы просто частным мнением, но Касперская на тот момент возглавляла подгруппу «Интернет + Общество» в рабочей группе под кураторством помощника президента России.
Аргументация простая – как только пользователь загрузил какие-то свои данные в интернет, они перестают ему принадлежать. А учитывая опыт других стран (например, Китая), было бы логично передавать все эти данные государству. Правда, в дальнейшем об этом ничего не было слышно – либо идея «заглохла», либо ее решили дальше не подвергать огласке.
Что касается Китая, там действительно есть истории о том, как Facebook согласился сотрудничать с правительством (передавать ему некоторую важную информацию пользователей), а Skype вообще отслеживает «неугодные» слова в сообщениях по определенному справочнику, и цензурирует их.
Последнее, о чем говорили в России в контексте Big Data – это предстоящая перепись населения, в ходе которой обещали использовать наработки по таким технологиям. Кроме прочего, переписчики будут пользоваться планшетными ПК, а данные будут как-то централизованно обрабатываться с использованием технологий Big Data.
Но главное – «большие данные» в России активно используются государственными органами в рамках всем известной «цифровизации». В частности, эти технологии уже используют в ФНС (которая вообще считается лидером по «цифровизации»), ФСБ, Пенсионном фонде, Фонде ОМС, Следственном комитете и некоторых других органах. Правда, конкретные результаты пока остаются по большей части за кадром – серьезных перемен в медицине не видно, а в налоговой службе все так же часто бывают сбои.
Кроме того, об использовании Big Data и технологий искусственного интеллекта часто говорят в «Сбербанке» – по словам руководства, это позволило сократить почти всех менеджеров среднего звена, а решения о выдаче кредита теперь часто принимает ИИ. Но снова, для рядовых клиентов «Сбербанк» – это все еще не самый современный банк со странным подходом к клиентам и частыми сбоями.
Big data — простыми словами
В современном мире Big data — социально-экономический феномен, который связан с тем, что появились новые технологические возможности для анализа огромного количества данных.
Для простоты понимания представьте супермаркет, в котором все товары лежат не в привычном вам порядке. Хлеб рядом с фруктами, томатная паста около замороженной пиццы, жидкость для розжига напротив стеллажа с тампонами, на котором помимо прочих стоит авокадо, тофу или грибы шиитаке. Big data расставляют всё по своим местам и помогают вам найти ореховое молоко, узнать стоимость и срок годности, а еще — кто, кроме вас, покупает такое молоко и чем оно лучше молока коровьего.
Кеннет Кукьер: Большие данные — лучшие данные
Что такое Big data?
Большие данные — технология обработки информации, которая превосходит сотни терабайт и со временем растет в геометрической прогрессии.
Такие данные настолько велики и сложны, что ни один из традиционных инструментов управления данными не может их хранить или эффективно обрабатывать. Проанализировать этот объем человек не способен. Для этого разработаны специальные алгоритмы, которые после анализа больших данных дают человеку понятные результаты.
В Big Data входят петабайты (1024 терабайта) или эксабайты (1024 петабайта) информации, из которых состоят миллиарды или триллионы записей миллионов людей и все из разных источников (Интернет, продажи, контакт-центр, социальные сети, мобильные устройства). Как правило, информация слабо структурирована и часто неполная и недоступная.
Когда стоит внедрять платформы для анализа больших данных
Обычно в компании у каждой команды есть инструмент для упорядочивания процессов и совместной работы над задачами. Платформы обработки данных — такой же нужный инструмент для дата-сайентистов, как система контроля исходного кода для разработчиков, CRM для отдела продаж и helpdesk для технической поддержки.
Например, в небольших компаниях вместо CRM используются excel-файлы или облачные kanban-сервисы. Разные менеджеры могут использовать разные инструменты. На определенном этапе возникают проблемы: информация не хранится в одном месте, нет единого доступа к ней у руководителей, файлы увеличиваются в объеме, в них долго искать информацию и трудно масштабировать такую систему.
Схожие трудности возникают и в data science-проектах. Вот признаки того, что вам пора начать использовать платформу анализа больших данных:
- Снижение продуктивности. Если вы замечаете, что инструментов становится слишком много, вы тратите много времени на рутинные задачи, а время на обработку данных и обслуживание разных инструментов только растет — вероятнее всего, вам пора переходить на DS-платформу.
- Трудности масштабирования. Когда вам необходимо тиражировать разработанное приложение на другие направления бизнеса или один из этапов обработки данных потребовал больше вычислительных ресурсов, то возникает потребность в масштабировании. Если вам нужно масштабироваться, но вы не очень хорошо представляете, как именно это сделать, то платформа просто необходима.
- Прозрачность. Если в команде дата сайентистов начинаются проблемы с коммуникацией, то это говорит об отсутствии централизованных знаний, которыми можно легко делиться между собой. Современные платформы предоставляют доступ разным сотрудникам, вовлеченным в проект.
Рынок data science-платформ растет вместе с рынком искусственного интеллекта и углубленной аналитики данных. По оценкам агентства Markets and Markets, рынок платформ для анализа больших данных растет в среднем на 30% в год. Появляются новые продукты, которые разработчики называют платформами для анализа данных или data science platform, и неподготовленному человеку может быть сложно в них разобраться.
Это искусственный интеллект?
Скорее, нет — но их не следует ставить далеко друг от друга. Нет — потому что искусственный интеллект, как предполагается — это некий субъект обработки информации. «Мозг», который сам «решает» (а не за него «решают» — пусть и «научили» до этого), что обрабатывать и зачем.
А Big Data – это объект обработки данных, чистая информация. Вместе с тем, во всех случаях, когда ее обрабатывает «интеллект» — качество конечного продукта такой обработки будет определенно выше, чем если бы данные были «простыми» (как вариант — малыми по объему, не обновляемыми и однообразными).
Таким образом, развитие подходов к применению «больших данных» — важнейший фактор развития технологий искусственного интеллекта, машинного обучения, эффективного делегирования различных интеллектуальных функций человека компьютеру. Между Big Data и AI теперь установлена неразрывная связь.
История вопроса и определение термина
При этом уже сейчас термин не использует только ленивый. Особенно часто не по делу термин используют маркетологи. Так что же такое Big Data на самом деле? Раз уж я решил системно изложить и осветить вопрос – необходимо определиться с понятием.
В своей практике я встречался с разными определениями:
· Big Data – это когда данных больше, чем 100Гб (500Гб, 1ТБ, кому что нравится)
· Big Data – это такие данные, которые невозможно обрабатывать в Excel
· Big Data – это такие данные, которые невозможно обработать на одном компьютере
И даже такие:
· Вig Data – это вообще любые данные.
· Big Data не существует, ее придумали маркетологи.
Таким образом под Big Data я буду понимать не какой-то конкретный объём данных и даже не сами данные, а методы их обработки, которые позволяют распредёлено обрабатывать информацию. Эти методы можно применить как к огромным массивам данных (таким как содержание всех страниц в интернете), так и к маленьким (таким как содержимое этой статьи).
Приведу несколько примеров того, что может быть источником данных, для которых необходимы методы работы с большими данными:
· Логи поведения пользователей в интернете
· GPS-сигналы от автомобилей для транспортной компании
· Данные, снимаемые с датчиков в большом адронном коллайдере
· Оцифрованные книги в Российской Государственной Библиотеке
· Информация о транзакциях всех клиентов банка
· Информация о всех покупках в крупной ритейл сети и т.д.
Количество источников данных стремительно растёт, а значит технологии их обработки становятся всё более востребованными.
Big Data (БигДата): что это такое
Термину Биг Дата (Big Data) – впервые употребленному, к слову, в том же журнале Nature его редактором Клиффордом Линчем в 2008 году — очень сложно дать определение. И, более того, наверное, невозможно так, чтобы оно не вызвало возражений в среде неравнодушных лиц
Но если попробовать сделать это очень осторожно, то правомерно предположить, что «большие данные» — это некие статистически значимые объемы информации, которые могут быть обработаны в рамках некоей полезной предикативной функции
Например — по прогнозированию территории заболеваемости ОРВИ. По ценам на билеты.
«Большие данные» могут быть как структурированными, так и неструктурированными. А обрабатываться — любым способом: нет никаких общих алгоритмов касательно этой процедуры. Популярен тезис, по которому к «большим данным» совершенно точно относятся те, на основании которых (после обработки которых) у человека появляются новые знания — инсайты. О которых он, не имея в распоряжении Big Data, даже не догадался бы.
Big Data правомерно считать «большими данными» просто потому, что они большие на самом деле: речь может идти об обработке огромного количества гигабайт информации, причем за короткий промежуток времени, с использованием больших вычислительных мощностей. Такую особенность некоторые исследователи называют одним из ключевых критериев отличий «больших данных» от «обычных» — которые обрабатываются последовательно, небольшими порциями (поскольку мощности для этого задействуются значительно меньшие).
При этом, и «большие данные» и соответствующие вычислительные мощности — стали доступны людям сравнительно недавно. Еще буквально 15-20 лет назад их не было — из-за недостаточной пропускной способности интернета, из-за слишком дорогой себестоимости отдельных «мощностей», особенно на конечных участках сбора информации.
Выросло количество потенциальных и реальных носителей такой информации — сейчас оно, как минимум, сопоставимо количеству людей, живущих на планете Земля. У большинства есть смартфон или иной интерактивный гаджет — собирающий и позволяющий собирать широкий спектр данных, которые обязательно передаются в какую-нибудь информационную систему. Раньше у людей не было ни финансовой, ни технической возможности быть носителями таких данных.
Выросла интенсивность обработки такой информации — сейчас интерактивные гаджеты функционируют и что-то собирают практически круглосуточно. Раньше человек подходил к компьютеру — если он у него был, может быть, на пару часов в сутки — и, надо сказать, как правило, мало что думал о предикативной функции в отношении чего-либо.
Есть подход, по которому в отношении «больших данных» выделяют следующие ключевые признаки:
- большой объем;
- постоянное обновление исходной информации (вследствие чего ее обработка становится непрерывной);
- разнообразие исходной информации (то есть, она может быть по сути разнотипной — но анализироваться впоследствии с общем контексте).
Так или иначе, Big Data / Биг Дата / «большие данные» — это новое явление в мире современных технологий. Результат развития этих самых технологий — причем, уже результат практический, реализуемый вне контекста каких-либо теоретических обоснований.
Перспективы и тенденции развития Big data
В 2017 году, когда большие данные перестали быть чем-то новым и неизведанным, их важность не только не уменьшилась, а еще более возросла. Теперь эксперты делают ставки на то, что анализ больших объемов данных станет доступным не только для организаций-гигантов, но и для представителей малого и среднего бизнеса
Такой подход планируется реализовать с помощью следующих составляющих:
Облачные хранилища
Хранение и обработка данных становятся более быстрыми и экономичными – по сравнению с расходами на содержание собственного дата-центра и возможное расширение персонала аренда облака представляется гораздо более дешевой альтернативой.
Использование Dark Data
Так называемые «темные данные» – вся неоцифрованная информация о компании, которая не играет ключевой роли при непосредственном ее использовании, но может послужить причиной для перехода на новый формат хранения сведений.
Искусственный интеллект и Deep Learning
Технология обучения машинного интеллекта, подражающая структуре и работе человеческого мозга, как нельзя лучше подходит для обработки большого объема постоянно меняющейся информации. В этом случае машина сделает все то же самое, что должен был бы сделать человек, но при этом вероятность ошибки значительно снижается.
Blockchain
Эта технология позволяет ускорить и упростить многочисленные интернет-транзакции, в том числе международные. Еще один плюс Блокчейна в том, что благодаря ему снижаются затраты на проведение транзакций.
Самообслуживание и снижение цен
В 2017 году планируется внедрить «платформы самообслуживания» – это бесплатные площадки, где представители малого и среднего бизнеса смогут самостоятельно оценить хранящиеся у них данные и систематизировать их.
Особенности применения технологии больших данных в отличие от работы с базами данных
Для реализации технологии Big Data в настоящее время разработаны архитектуры вычислительных систем и необходимое информационное и программное обеспечение. В их число входят:
- Hadoop — реализация модели распределенных вычислений MapReduce и набор различных утилит и библиотек для выполнения программ и распределенных вычислений;
- MapReduce — framework для вычисления распределенных задач;
- Pig — платформа для создания MapReduce приложений с помощью Hadoop;
- Hive, Impala — инфраструктуры хранилища данных, построенного на основе Hadoop;
- Spark — инструментарий для распределенного анализа данных;
- NoSQL базы данных: HBase, MongoDB, Apache Cassandra.
Минимальные навыки и обучение с нуля
Если карьерный путь начинается из другой сферы, в первую очередь необходимо прокачать знания в дискретной математике и статистике.
Когда аналитик работает с большими данными, он использует различные технологии, в зависимости от конкретной задачи, которую сейчас выполняет. Некоторые из многих инструментов включают (но не ограничиваются ими):
- MapReduce.
- Sqoop.
- Impala.
- Pig.
- HBase.
- Apache Spark.
- HDFS.
- YARN.
- Flume.
Для анализа и интерпретации данных аналитики тратят много времени на работу с множеством аналитических и бизнес-инструментов, таких как Microsoft Excel, MS Office, SAS, Tableau, QlikView, Hadoop, MongoDB, Cassandra, Hive, Pig, SQL.
Следует изучить один язык программирования (Python/Ruby/Perl). Как только он будет освоен, процесс обучения другим языкам будет проще.
Актуальная информация в первую очередь появляется в англоязычных комьюнити. Знание английского языка необходимо не только для изучения материалов по теме, но и для общения с зарубежными коллегами.
Кто и как собирает данные?
Всю работу можно условно разделить на три этапа: интеграция, управление и анализ.
Этап 1. Интеграция
На первом этапе компания должна определить цели внедрения Big Data, выбрать инструменты сбора информации, а также связать их со своими источниками поступающих данных.
Этап 2. Управление
На этом этапе выбирается платформа для хранения информации. Компании могут использовать локальные хранилища, публичные или частные облачные сервисы.
Этап 3. Аналитика
Большие данные должны работать на бизнес, однако они начинают приносить пользу после анализа. Это заключительный этап взаимодействия с ними.




